Chaos engineering and chaos testing have grown in popularity to ensure high-quality software when it is already in production. This relatively recent approach has improved many businesses and transformed how we assess software resilience.
Who should be in charge of this effort, and where does it belong in a DevOps environment? This post will delve deeper into these issues. Also, keep reading more about chaos testing, its benefits, and how it works to understand more about it.

What is Chaos Testing?
Chaos testing, also known as chaos engineering, is a highly disciplined approach to testing the integrity of a system by proactively simulating and recognizing failures in a specific environment before they cause unplanned downtime or a negative customer experience.
Chaos Testing, also known as Chaos Engineering, is a methodology that involves running controlled experiments to test software systems’ resilience to unpredictable, real-world events.
When using chaos engineering, DevOps and IT teams must set up a system of monitoring tools and conduct active chaos testing in a production environment.
Teams can see realistic simulations of how their software or service reacts to various pressures and stresses in this way. The goal of chaos engineering is to identify potential weaknesses in software systems before they cause major disruptions or failures.
Development teams can use chaos experiments to simulate different types of failures and monitor how the system responds.
For example, one popular tool for chaos testing is Chaos Mesh, which allows developers to simulate various types of faults, including network delays, packet loss, and application crashes. It can help teams identify issues related to scalability, availability, and performance testing.
Chaos Engineering experiments are typically carried out by injecting faults or errors into a system’s code or infrastructure.
Which can help teams identify and address potential issues before they affect end users. The Netflix team is one of the pioneers of this process and has used fault injection and chaos experiments to improve their systems’ resiliency.
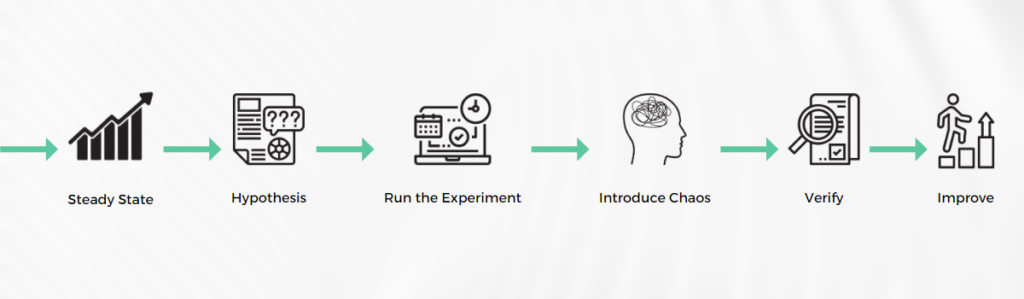
There are five main principles of chaos engineering:
- Establish a steady state and make sure your system functions. You should define a “steady state” or control as an objectively measurable system output that denotes typical operational behavior (below a one percent error rate).
- Assume that the system’s steady state will persist. It is necessary to assume that a steady state will persist under both control and experimental circumstances once it has been identified.
- Limit the impact on your users. It’s important to actively try to break or interrupt the system during chaos testing to reduce the blast radius and any adverse effects on your users. Your team will take in-charge to ensure that each test is focused on a particular area, and you should prepare yourself to respond to incidents as needed.
- Introduce chaos. You can begin running your chaos testing applications once you confirm that your system is operational, your team is ready, and the blast radius has been contained. A server crash, broken hardware, severed network connections, and other real-world occurrences should simulate using different variables that you introduce. It is best to test in a production environment in order to see how your service or application will react to these situations without affecting the live version and current users.
- Continue to monitor and repeat. The secret to chaos engineering is to test frequently while introducing chaos to identify any flaws in your system. Chaos engineering aims to refute your second hypothesis while simultaneously creating a stronger and more reliable system.
How Chaos Engineering Works
Chaos engineering is similar to stress testing in that it seeks to find and fix network or system problems. Unlike stress testing, Chaos engineering tests and makes corrections to a system as a whole.
Chaos engineering looks at issues whose potential causes appear to be limitless. Beyond the obvious problems, it tests distributed systems against sets of fewer problems or problems themselves. The objective is to learn more about the software.
Usually, the procedure has several steps:
- Set the baseline. Establish a baseline first. The testers must specify what constitutes a typical working state and define how the system should behave under ideal circumstances.
- Make a hypothesis. Consider one or more potential weaknesses, then propose a theory about how those weaknesses might affect the situation. For instance, software testers want to know what will happen in the event of a significant increase in traffic.
- Test. Run tests to determine the effects of a significant spike. The experiments might identify a flaw in a crucial procedure or a surprising cause-and-effect connection. For instance, an issue with storage performance might be discovered by simulating a traffic spike.
- Evaluate. Determine which issues need to fix by measuring and evaluating how well the hypothesis holds.
Teams of chaos engineers systematically conduct experiments, testing the following:
- Things they are aware of and comprehend
- The matters that they are aware of but do not fully comprehend
- the things they are unaware of but understand
- the things they do not fully understand and are not fully aware of
They assess the effectiveness and integrity of the system using “what if” scenarios that could result in faults and failures.

How Does Chaos Testing Operate in DevOps?
A DevOps framework works well with chaos engineering. Basically, a DevOps engineer like the XA is responsible for chaos engineering (Experience Assurance Professional). This individual is the in-charge of creating the various testing scenarios, carrying out the tests, and monitoring the results. They are also in charge of making sure the customer is affected as little as possible.
The DevOps engineer must walk a very fine line while testing. One method involves trying to make the system crash while introducing chaos to test the system’s integrity (hence, why this is best done in a production environment). On the other hand, conducting haphazard or careless tests can result in a system crash and degrade the user experience.
What is Chaos Monkey and How Does it Work?
To meet the need for continuous and consistent testing, Netflix started chaos testing their system during their migration to AWS. To this end, they created various “chaos monkeys.” These chaos monkeys were introduced into software to simulate multiple real-world scenarios and find specific issues, such as network delays, instances, missing data segments, etc.
Each chaos monkey had a unique name and task, such as:
- Latency Monkey: Creates artificial delays.
- Conformity and Security Monkeys: Track down and eliminate instances that violate best practices.
- Janitor monkey: clears out and gets rid of waste materials.
- Chaos Gorilla: Simulates the loss of all Amazon availability zones.
- These and other chaos monkeys are now known as the Simian Army
Examples of Chaos Engineering
The distributed system’s behavior under resource constraints or the presence of a single point of failure can also be tested using chaos engineering. If the system fails, changes to the design can be made by developers. The test is repeated to confirm the desired outcomes after the changes are made.
One notable system failure in real life had a connection to chaos engineering. In 2015, we saw a problem with Amazon’s DynamoDB’s availability in one of its regional zones. Over 20 Amazon Web Services in that region that relied on DynamoDB failed due to that error.
Websites that use these services, like Netflix, were unavailable for several hours. On the other hand, Netflix fared better than other websites because it had created and used a chaos engineering tool called Chaos Kong to foresee such a contingency.
The entire AWS availability zone, which consists of the AWS data centers that serve a specific geographic area, is disabled by Chaos Kong. Netflix had experience replying to regional outages like the one the DynamoDB problem caused thanks to their use of the tool. It is common to use the company’s capacity to handle the outage to highlight the significance of chaos engineering.
The Advantages and Disadvantages of Chaos Testing?
Some of the biggest IT and DevOps teams in the market are becoming more interested in chaos engineering. It’s not always the best option for every team and circumstance.
The benefits of chaos engineering include increased system reliability, faster incident response times, and improved customer satisfaction. By proactively identifying potential issues, development teams can save time and resources in the long run by avoiding costly downtime and reputational damage.
The benefits of chaos testing include:
- IT and DevOps teams are able to recognize and solve issues that other testing methods might miss
- Due to proactive and ongoing testing, unplanned downtime and outages are much less likely to occur
- Boosts the integrity of the system
- Excellent for scaling up large, complex systems (like cloud-based applications and services)
Disadvantages of chaos testing:
- Smaller systems or desktop software
- Services and programs that are not essential to the operation of the business
- Application environments without customer SLAs require 24-hour uptime
- Systems where mistakes are acceptable as long as they are fixed by the end of the day
Get Started With Chaos Testing
Chaos engineering has developed into a robust and wonderful technique in the current software development lifecycle that may assist organizations in operating distributed systems as well as improves the resiliency, adaptability, and velocity of the system.
Together with these advantages, it has also enabled us to fix the problem before it affects the system. For improved results, chaos engineering implementation is crucial and should be embraced.
Are you eager to begin testing your own system under chaotic conditions? It’s crucial to assess whether chaos testing and engineering are appropriate for your team and business before rushing out your own army of chaos monkeys.
It has been demonstrated that chaos engineering is incredibly effective at enhancing the integrity of huge and complex systems, providing advantages like quicker incidence response times, fewer unscheduled outages, and the highest level of scalability flexibility. For desktop software or smaller systems, chaos testing might not be required.
The article above gave a basic overview of chaotic engineering and showed how it can provide the system with fresh perspectives.
I hope you learned something about chaotic engineering from this article. There is still a great deal to learn about this broad topic.