Imagine this- You’re trying to transfer funds through your banking app during peak hours, only for the app to crash just as you’re about to complete the transaction. Or consider a hospital’s patient management system becoming unresponsive during an emergency. These real-world software failures aren’t just frustrating, they can be life-threatening or financially disastrous. They underscore a vital but often underappreciated part of software quality assurance- Reliability Testing. In this blog, we will talk in detail about reliability testing, its types, objectives and more. Read along to find out.
What Is Reliability Testing?
Alt text: Reliability testing
Reliability Testing is a type of software testing that ensures a system consistently performs as expected under defined conditions for a specified period. The focus isn’t just on whether a system works, but whether it continues to work reliably and without failure.
Especially in mission-critical systems, such as finance, healthcare, or aviation, reliability can mean the difference between success and catastrophe. Even in user-centric applications, poor reliability can lead to user churn and damage to the company’s reputation.
Objectives of Reliability Testing
Alt text: Objectives of reliability testing
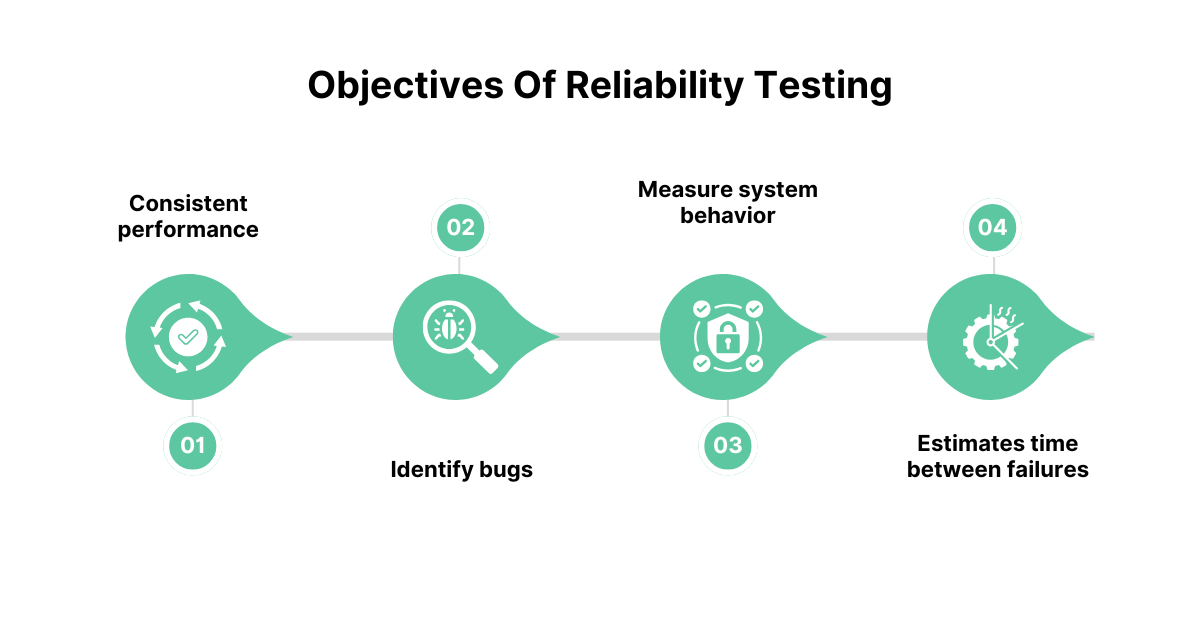
Reliability Testing plays a crucial role in verifying that software systems can deliver consistent, dependable performance over time. Here are some of the key objectives of reliability testing:
- Ensure the software performs consistently without failure
- Identify potential points of failure in a system
- Measure system behavior under different load and stress levels
- Estimate the time between failures (MTBF)
Types of Reliability Testing
Reliability Testing isn’t a single test. It’s a combination of different testing approaches designed to evaluate the system’s ability to function reliably under various conditions. Here’s a breakdown of the key types:
Feature Testing
Feature testing verifies that individual features of the application perform as expected, not just once but consistently across repeated uses and different scenarios. It’s especially important after updates or when the feature is heavily used.
Load Testing
This form of testing evaluates how the application performs when handling multiple simultaneous users or transactions. Load testing helps detect issues like slowdowns, bottlenecks, or failures when the system is under stress but still within its normal operating range.
Regression Testing
Whenever code changes are made, whether bug fixes or new features, regression testing confirms that previously working parts of the application still function reliably. This protects against introducing new bugs while improving or extending the software.
Stress Testing
Unlike load testing, stress testing goes beyond expected usage patterns to test how the system behaves under extreme conditions. It reveals how the software handles resource exhaustion, hardware failures, or peak traffic spikes- essential for resilience planning.
Recovery Testing
This type of testing simulates crashes, power losses, and other unexpected failures to assess the system’s ability to recover quickly and without data loss. A robust recovery strategy ensures users can return to normal operations with minimal disruption.
Key Reliability Metrics
Alt text: Key reliability metrics
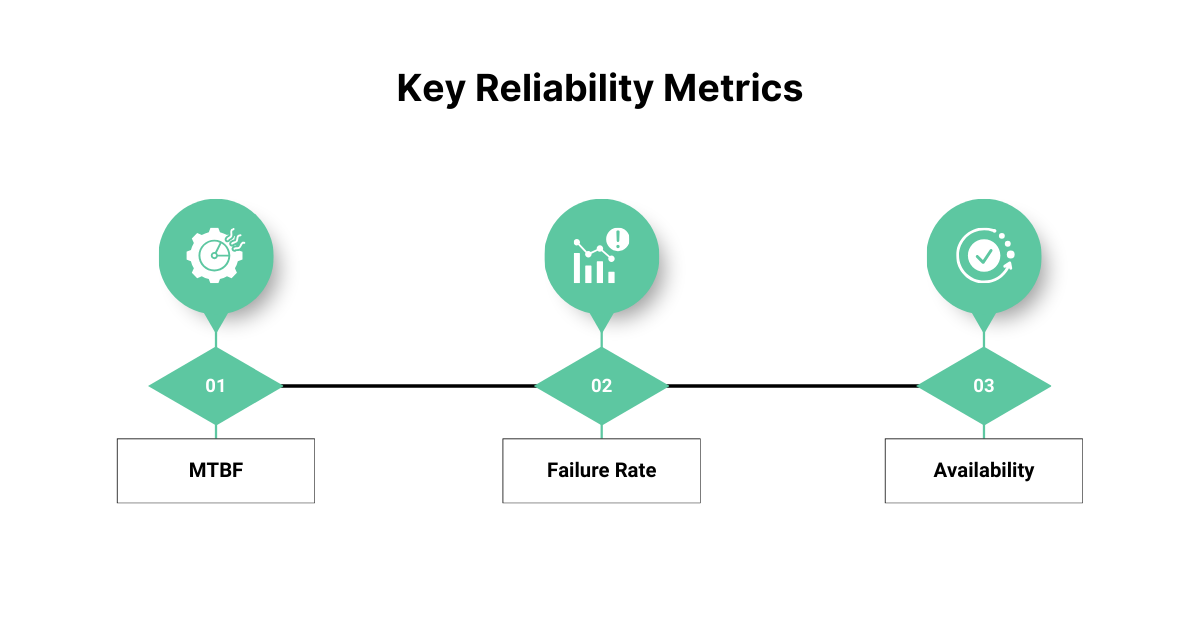
To accurately evaluate the reliability of a software system, it’s essential to measure and track specific metrics. These metrics provide quantifiable insights into how often failures occur, how long it takes to recover, and how available the system remains to users.
MTBF (Mean Time Between Failures)
MTBF is the average time that elapses between one failure and the next during normal operation. It is a direct indicator of how reliable a system is. A higher MTBF means the system can operate for longer periods without crashing or experiencing issues. It’s particularly useful in predicting and planning maintenance windows.
Example: If a server fails every 500 hours on average, the MTBF is 500 hours.
MTTR (Mean Time To Repair)
MTTR is the average amount of time it takes to diagnose, fix, and recover from a system failure. MTTR affects user experience and system availability. The faster issues are resolved, the less disruption users face. Monitoring MTTR also helps in evaluating the efficiency of your incident response process.
Example: If it takes an average of 2 hours to fix a failure, your MTTR is 2 hours.
Failure Rate
The number of failures that occur within a specific period or per unit of operation time is the failure rate. This metric gives a clear view of how prone the system is to failure. A high failure rate often indicates deeper underlying issues such as poor architecture, inadequate testing, or faulty integrations.
Example: If there are 10 failures in 1,000 hours of operation, the failure rate is 0.01 failures/hour.
Probability Of Failure On Demand (POFOD)
POFOD measures the likelihood that a system will fail when a specific service is requested. It is especially relevant in systems where demands are intermittent but critical, such as safety or emergency response systems.
Example: A POFOD of 0.002 means there’s a 0.2% chance the system will fail to respond correctly when needed.
Availability
Availability is the percentage of time a system is fully operational and accessible. High availability is critical for user-facing applications, especially those that provide services in real-time (e.g., banking apps, e-commerce platforms). This metric reflects both the reliability and maintainability of a system.
Formula:
Availability (%) = [MTBF / (MTBF + MTTR)] × 100
Example: A system with a 99.95% availability is down for only ~4.4 hours in a year.
Reliability Testing Process
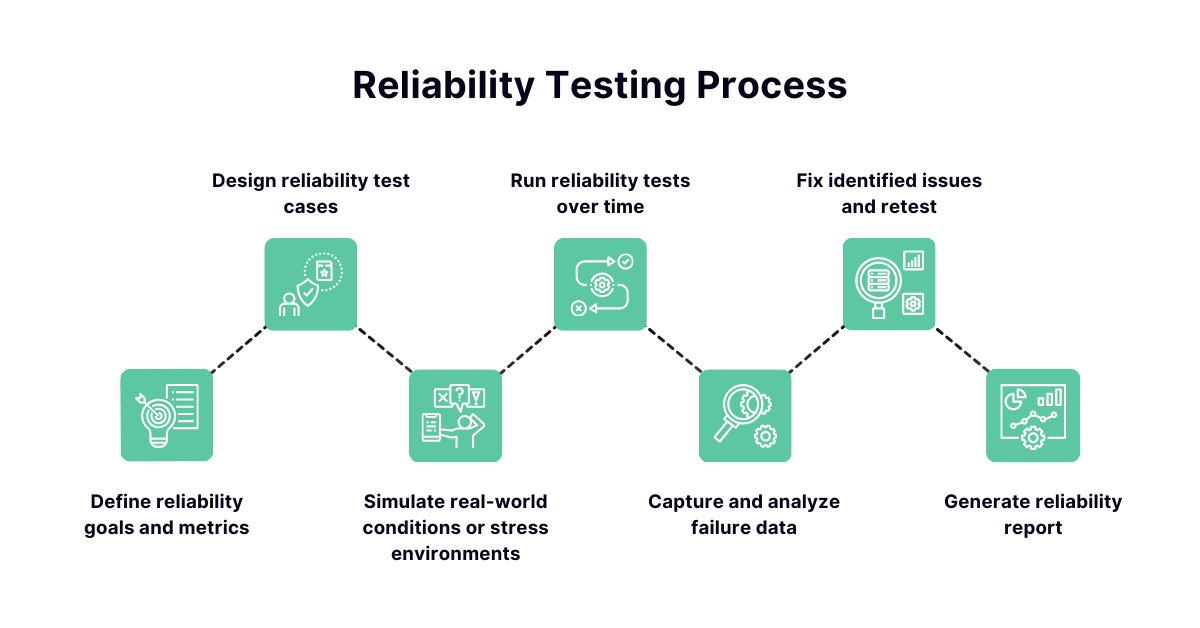
Alt text: Reliability testing process
Conducting reliability testing effectively requires a structured approach. It’s not just about running a few tests. It’s about strategically planning and executing tests over time to assess long-term system behavior under real-world conditions.
Define reliability goals and metrics
Begin by establishing what “reliable” means for your specific system. These goals should align with business requirements and user expectations. Determine key metrics such as MTBF, MTTR, failure rate, and system availability. Defining clear targets helps ensure testing is focused and measurable.
Design reliability test cases
Create detailed test scenarios that mimic typical and edge-case user behaviors. Here’s what you should include:
- Functional workflows
- Heavy usage scenarios
- Interaction with external systems
Test cases should be designed to run continuously or repeatedly over extended periods to simulate long-term usage.
Simulate real-world conditions or stress environments
To evaluate how the software holds up under actual usage patterns, create an environment that mirrors production. Introduce variable loads, network fluctuations, database activity, and third-party integrations. In some cases, stress conditions may be added to see how the system behaves under abnormal or extreme usage.
Run reliability tests over time
Run the designed tests for prolonged periods, sometimes days or even weeks. Reliability issues often emerge only after hours or days of operation. Monitoring should be continuous, capturing real-time data on performance, failures, and system health.
Capture and analyze failure data
As tests run, collect data on any system crashes, errors, slowdowns, or other abnormal behaviors. Analyze the failure logs to identify:
- Root causes
- Frequency of failures
- Patterns or common triggers
This step is crucial for improving the software’s reliability through targeted fixes.
Fix identified issues and retest
Once problem areas are identified, the development team fixes them, and the test cycle begins again. Re-running tests ensures that the issues have been resolved without introducing new ones and that the overall system reliability has improved.
Generate reliability report
At the end of the software testing cycle, compile a detailed report covering:
- Test scenarios and conditions
- Metrics captured (MTBF, MTTR, failure rate)
- Issues found and resolved
- Overall system performance
This report provides stakeholders with a comprehensive view of the system’s readiness and long-term stability.
How to Build a Reliability Test Plan
A well-structured reliability test plan is the foundation of a successful testing process. It ensures that everyone who is involved- QA, development, and stakeholders- are aligned on the objectives, scope, and expectations.
Purpose
Different systems have different reliability requirements. For example, a healthcare monitoring system might require near-zero downtime, while an internal HR tool might tolerate brief outages. Clearly stating the purpose helps set realistic expectations and guides the test approach.
Scope
Outline which modules, components, or user scenarios are within the scope of reliability testing. Also, mention any exclusions.
Include: API layer, database interactions, checkout process
Exclude: UI responsiveness (covered in performance testing)
Test Strategy
Detail the types of reliability tests to be performed. This includes a mix of:
- Load Testing: To evaluate behavior under normal and high user volumes
- Stress Testing: To test system limits
- Feature & Regression Testing: To verify functionality remains stable over time
- Recovery Testing: To assess how well the system bounces back from failures
Explain when and how these will be executed during the test cycle.
Metrics
List the key metrics that will define success or failure.
- MTBF (Mean Time Between Failures)
- MTTR (Mean Time To Repair)
- Failure rate
- Uptime/Availability targets
Environments
Describe the testing environments used. Use environments that closely mimic production, including hardware specs, network conditions, third-party integrations, and traffic patterns.
Schedule
Lay out the test timeline and frequency.
- Duration: How long each test will run (e.g., 24-hour test cycles, weekly runs)
- Frequency: How often tests will be run (daily, after deployments, etc.)
- Automation: What parts of the test will be automated vs. manual
Entry and Exit Criteria
Set clear benchmarks for when testing begins and ends.
- Entry Criteria: System must pass all functional tests, be stable in staging, and meet pre-test config
- Exit Criteria: No critical failures, MTBF ≥ target, system maintains uptime threshold, issues logged and resolved
Tools & Resources
List the tools, teams, and infrastructure required.
- Tools: JMeter, LoadRunner, K6, Gatling, Reliability Workbench
- Resources: Test data, simulated user traffic, monitoring dashboards
- Teams: QA engineers, DevOps, developers for bug fixing
When To Perform Reliability Testing In SDLC?
Timing is everything when it comes to reliability testing. To maximize its effectiveness, it should be strategically integrated at multiple stages of the Software Development Life Cycle (SDLC). Testing too early might not reveal much, and testing too late might delay releases or miss critical issues.
Here’s when you should perform reliability testing for the greatest impact:
- Once the system components are combined, begin testing to ensure they interact reliably over time without causing unexpected failures.
- While testing for speed and responsiveness, extend the duration to assess how the system performs under sustained load and usage.
- Confirm that the system is not only functionally complete but also stable enough for end users to test without frequent crashes or glitches.
- Run final reliability tests in a staging environment that mirrors production. This helps catch last-minute issues that could affect real users.
- Continue to track reliability in the live environment using monitoring tools. This helps detect real-world failures and improve future releases.
Tools for Reliability Testing
Using the right tools is essential for effective reliability testing. Here are some popular tools for reliability testing:
- LoadRunner: A performance and load testing tool that simulates thousands of users interacting with your application. LoadRunner is ideal for running extended stress and load tests to monitor system reliability under pressure.
- Apache JMeter: A widely used tool for performance and load testing web applications. JMeter allows you to simulate real user behavior over time and collect data on stability and throughput.
- Selenium: Primarily a functional testing tool, Selenium is also useful for reliability regression testing, ensuring that automated test cases for core features continue to pass over time and across releases.
- TestLink: Helps document, organize, and manage your reliability test cases. It also tracks results, making it easier to analyze test coverage and outcomes over time.
- QA Touch: A modern test management tool that integrates with automation frameworks and issue trackers. It helps teams plan, manage, and track reliability testing efforts more efficiently with support for traceability, customizable workflows, and insightful reporting.
- Reliability Workbench: Specialized for reliability engineering. A comprehensive suite that focuses on advanced reliability analysis, including failure modes, MTBF calculations, and fault tree analysis.
- QTP (Quick Test Professional) / UFT (Unified Functional Testing): Automates UI-based test scenarios and supports repeated execution. It’s especially useful for automating long-duration reliability tests of desktop and web applications.
Benefits of Reliability Testing
Investing in reliability testing brings numerous advantages, not just for the QA team but for the entire product lifecycle and user experience.
- When users encounter fewer crashes and consistent performance, their confidence in the product grows. Reliable software fosters a positive reputation and keeps users engaged, increasing customer retention.
- Reliability testing helps identify and fix issues before they cause system outages or need costly emergency patches, reducing downtime and lowering long-term maintenance expenses.
- By uncovering hidden vulnerabilities and weaknesses, reliability testing strengthens the system’s overall architecture, ensuring it can handle heavy or prolonged use without failure.
- Finding potential failures before deployment reduces the risk of severe issues affecting end users, especially in mission-critical applications like healthcare, finance, and e-commerce.
- High reliability directly influences how customers perceive your product and brand. Stable and reliable software improves brand credibility and enhances the quality of the product in the market.
Challenges in Reliability Testing
While reliability testing is essential for ensuring the long-term success of software, it comes with its own set of challenges. Here are some common hurdles QA teams face:
Difficulty simulating long-term usage in test environments
Unlike performance or functional tests, reliability testing often requires simulating days, weeks, or even months of continuous operation, which is difficult to replicate in a controlled test environment.
Use cloud-based testing environments that can simulate extended usage over multiple instances, or set up a series of long-duration tests.
High resource and time requirements
Reliability testing often involves running multiple tests for extended periods, which can consume significant computing power, time, and human resources. Continuous testing cycles can be both resource-intensive and costly.
Automation and utilizing cloud services can help reduce manual efforts and speed up test cycles.
Incomplete or unclear reliability requirements
Some organizations may not have well-defined reliability goals or metrics, leading to ambiguous testing criteria. Without clear expectations, it can be challenging to determine the effectiveness of the tests.
Work closely with stakeholders during the planning phase to define clear, measurable reliability objectives, including acceptable MTBF, MTTR, and uptime targets.
Complex integration of third-party systems
Many applications rely on third-party integrations (APIs, services, etc.), and ensuring these external systems perform reliably over time can be challenging. Testing may require additional coordination and resources.
Focus on testing both the primary system and its external dependencies. Consider using stubs or mocks for third-party systems to test specific integration points.
Real-World Examples of Reliability Testing
Reliability testing is critical in industries where system failures can have significant consequences. Below are real and hypothetical examples where reliability testing played a crucial role in ensuring continuous operation and user satisfaction across various sectors:
Airline Ticket Booking System
An airline company conducted reliability testing on its online booking platform before the peak travel season (e.g., summer or holiday periods). The goal was to ensure the platform could handle thousands of concurrent users, transactions, and real-time seat availability checks without crashing or slowing down.
Reliability Testing Role:
- Simulated high traffic conditions to test system performance during peak usage.
- Verified system uptime and response times over extended periods.
- Conducted stress tests to ensure the platform could handle extreme scenarios like last-minute booking surges.
Outcome: The airline successfully prevented website crashes during peak booking times, maintaining customer trust and satisfaction.
Healthcare Management System
A healthcare provider needed to ensure that its patient management and scheduling system could operate continuously without failures, especially during critical hours when doctors and staff are heavily relying on the system to access patient data and manage appointments.
Reliability Testing Role:
- Conducted long-duration reliability testing to verify the system could run without crashes during busy periods (e.g., morning shifts).
- Tested system performance under varying load levels, including simultaneous patient record retrieval and appointment scheduling.
- Ensured data accuracy and integrity even after extended usage.
Outcome: The healthcare system demonstrated robust performance, allowing healthcare professionals to rely on the system for patient management without downtime, especially during critical care hours.
Online Learning Platform
An online learning platform, especially during the beginning of a new semester, needs to ensure that its website and learning management system (LMS) can handle the large number of simultaneous logins, video streams, and interaction between students and instructors.
Reliability Testing Role:
- Simulated peak login and video streaming scenarios for thousands of users, ensuring the platform can handle the load without performance degradation.
- Tested system recovery after network failures or sudden drops in connectivity.
- Measured the reliability of core features like video playback, messaging, and content downloads under continuous use.
Outcome: The platform delivered uninterrupted access to learning materials and real-time student-teacher interactions, ensuring students could continue learning without disruptions.
E-Commerce Website
A major e-commerce platform preparing for a big sales event (e.g., Black Friday or Cyber Monday) conducts reliability testing to ensure that the website can handle massive traffic and process orders continuously, even during the event’s peak hours.
Reliability Testing Role:
- Performed load testing to simulate millions of users browsing, adding items to carts, and completing purchases.
- Ensured that the backend order-processing system could handle the load without failures.
- Ran stress tests beyond typical peak traffic levels to evaluate how the system reacts under extreme stress (e.g., unexpected spikes).
Outcome: The website handled millions of simultaneous visitors with minimal downtime, maintaining sales and customer satisfaction during the highly anticipated shopping event.
Reliability Testing vs. Performance Testing
Reliability testing focuses on long-term stability, while performance testing focuses on the system’s responsiveness and ability to handle load.
| Aspect | Reliability Testing | Performance Testing |
| Focus | Long-term consistency | System speed & responsiveness |
| Goal | Identify and minimize failure | Measure system under stress/load |
| Timeframe | Extended periods | Short bursts or scenarios |
| Failure Tolerance | Low | Moderate (temporary slowdowns) |
| Example | System crashes after 24 hrs | Slow response under 500 users |
Common Mistakes to Avoid in Reliability Testing
Reliability testing is crucial for ensuring software can perform consistently over time, but there are several common mistakes that can hinder its effectiveness. Avoiding these mistakes is key to successful reliability testing:
- Waiting until late in the Software Development Life Cycle (SDLC) to begin reliability testing can lead to unexpected failures just before deployment, resulting in costly fixes or delays.
- Running reliability tests for only short periods (e.g., a few hours) may not accurately reflect real-world usage, where systems are expected to perform consistently over days, weeks, or even months.
- Failing to properly document the results of reliability tests, including any system failures, makes it harder to track recurring issues and verify if fixes are successful.
Best Practices for Reliability Testing
To ensure your system performs reliably under all conditions, it’s important to follow best practices during reliability testing. Here are some practical tips and industry best practices:
- Set specific targets like uptime or MTBF (Mean Time Between Failures) that align with both business needs and user expectations.
- Automate repetitive, long-term tests and use manual testing for more complex or unusual scenarios.
- Continuously track system performance after launch to catch and fix issues early.
- Add reliability testing to your CI/CD pipeline to check for issues with every code update or deployment.
- Collect user feedback to spot issues that might not have been caught during testing and improve reliability.
Conclusion
Reliability Testing is more than just a checkbox- it’s a commitment to consistent, high-quality performance over time. As systems become more integrated and user expectations rise, ensuring reliability becomes non-negotiable.
QA Touch is a test management platform that can help streamline your reliability testing processes- from planning to execution and reporting- enabling you to ship resilient software that users can trust.Sign up today for free.